

什么是 Robots 协议?抛开定义,我们先来看两个巨人间的君子协定(并不是),有请淘宝和百度。
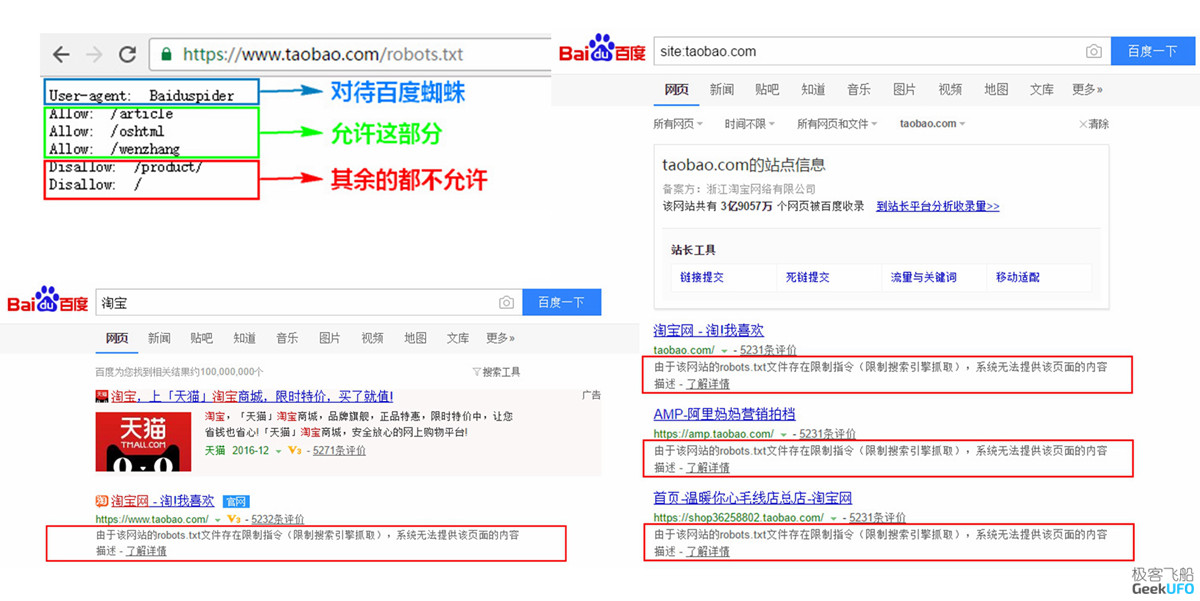
为什么百度不显示淘宝的网站描述?又是为何 BAT 中的 B 没有自己的消费品 B2C 平台?熊猫厂之间到底有着怎样鲜为人知的恩怨情仇?这一切究竟是人性的扭曲还是道德的沦丧?!![]()
事情还要从8年前说起,那时Jack马还没有带着阿里巴巴在华尔街和西方记者谈笑风生,每年的11月11日也不过是个单纯的直男癌纪念日,在人们的印象中Jack马还是位靠 B2C 闷声发大财的机智长者。但是,另一位叫做Robin李的有志之士对Jack马独霸国内电商市场表示不服!他决定搞个大新闻。
同年Robin李也推出了自家的电商平台,企图从Jack马手中拉走一批网民到他那里买买买。Jack马一看,不妙,但Robin李是按照了市场规则按照了基本法的,不能随随便便就拿来批判一番。Jack马虽说“I’m angry!”,但毕竟还是位有着丰富人生经验的长者,那是身经百战啦。Jack马狡黠地一笑,随即让程序猿在自己网站的 robots.txt 中添加了一句 User-agent: Baiduspider 回车 Disallow: / 。
就这样的一句,让Robin李引以为傲的搜索引擎再也不能名正言顺地收录Jack马的电商网站商品内容,而Jack马的电商平台依赖多年培养起来的用户习惯,让新老网购群体还是只能老老实实到他那里搜搜搜然后买买买。经此一役,敬仰Jack马的人更添几分敬仰,营销喵们也交口称赞“老哥,稳!”,这一稳便稳至今日。
其实在更近的 2012 年,一时闹得沸沸扬扬的“3B大战”就和 Robot 协议有关,不要问是哪“3B”,因为奇虎360如果叫奇虎260,那这个事件就该叫“2B大战”。在其中的一起纠纷中,原告百度以被告奇虎360违反 Robots 协议,强行抓取、复制其网站内容构成侵权为由,向法院提出了一个“小目标”——360赔我一个亿。最终,法院以奇虎360赔偿百度经济损失及合理支出70万元宣判。
阔(可)见,一切都和万握(恶)的 Robots 协议有关。
“这么危险,我们小站长还是不要碰了。”全文就到这里……
口合口合,好了正经的,其实 Robots 协议就是写在 robots.txt 格式文件中的一套规则,一般放在网站的根目录。它用于限制蜘蛛的行为,放什么蜘蛛又挡什么蜘蛛,放蜘蛛到哪里又禁止蜘蛛到哪里,都可以通过 robots.txt 文件自定义。对于我们这样的个人站长来说,明确地告诉蜘蛛“让你抓啥你就抓啥”以保证文章在搜索引擎中的正常收录,才是最主要的目标。
极客飞船建设的前期,我一直在捣鼓其他方面,对于重要的 robots.txt 竟随手搜了一篇就用,如此随意我一点都不脸红。赖于当时没有细看,直到一段时间后我发现百度只收录文章而不收录缩略图,这才意识到应该是 robots.txt 出了问题。找了一些资料参考并思考了半个下午后,酝酿出了一套满足我这小站需求的协议,在此把语句分享出来,如能起到抛砖引玉的作用便感欣慰:
User-agent: *
Allow: /robots.txt
Disallow: /wp-admin
Disallow: /wp-includes
Allow: /wp-includes/*.png*
Allow: /wp-includes/*.jpg*
Allow: /wp-includes/*.jpeg*
Allow: /wp-includes/*.gif*
Allow: /wp-includes/*.bmp*
Allow: /wp-includes/*.svg*
Allow: /wp-includes/*.ico*
Allow: /wp-includes/*.js*
Allow: /wp-includes/*.css*
Disallow: /wp-content
Allow: /wp-content/*.png*
Allow: /wp-content/*.jpg*
Allow: /wp-content/*.jpeg*
Allow: /wp-content/*.gif*
Allow: /wp-content/*.bmp*
Allow: /wp-content/*.svg*
Allow: /wp-content/*.ico*
Allow: /wp-content/*.js*
Allow: /wp-content/*.css*
Allow: /wp-content/*.ttf*
Allow: /wp-content/*.woff*
Disallow: /*/comment-page-*
Disallow: /*?replytocom=*
Disallow: /category/*/page/
Disallow: /tag/*/page/
Disallow: /*/trackback
Disallow: /feed
Disallow: /*/feed
Disallow: /comments/feed
Disallow: /?s=*
Disallow: /*/?s=*\
Disallow: /attachment/
Sitemap: http://geekufo.com/sitemap.xml
由于规则较长,我分成以下 7 个部分释义:

第 ① 部分:User-agent: *
释义:适用于所有蜘蛛;
第 ② 部分:Allow: /robots.txt
释义:允许抓取网站根目录下的 robots.txt 文件,一般蜘蛛会自动检测协议是否存在不需要写,此处以防万一;
第 ③ 部分:Disallow: /wp-admin
释义:禁止抓取 /wp-admin 目录下的所有文件,该目录有大量涉及权限的敏感文件;
第 ④ 部分:
Disallow: /wp-includes
Allow: /wp-includes/*.png*
Allow: /wp-includes/*.jpg*
Allow: /wp-includes/*.jpeg*
Allow: /wp-includes/*.gif*
Allow: /wp-includes/*.bmp*
Allow: /wp-includes/*.svg*
Allow: /wp-includes/*.ico*
Allow: /wp-includes/*.js*
Allow: /wp-includes/*.css*
释义:禁止抓取 /wp-includes 目录下的所有文件,除了 png、jpg、jpeg、gif、bmp、svg、ico等格式的图片,以及 js 和 css 文件,放行 js 和 css 文件是因为这样才能通过谷歌移动设备适应性之类的测试,你不会希望搜索引擎给网站标注“该网站不适合在移动设备上浏览”的;
第 ⑤ 部分:
Disallow: /wp-content
Allow: /wp-content/*.png*
Allow: /wp-content/*.jpg*
Allow: /wp-content/*.jpeg*
Allow: /wp-content/*.gif*
Allow: /wp-content/*.bmp*
Allow: /wp-content/*.svg*
Allow: /wp-content/*.ico*
Allow: /wp-content/*.js*
Allow: /wp-content/*.css*
Allow: /wp-content/*.ttf*
Allow: /wp-content/*.woff*
释义:禁止抓取 /wp-content 目录下的所有文件,除了 png、jpg、jpeg、gif、bmp、svg、ico等格式的图片,关系到是否在收录中显示缩略图;以及 js、css 文件和 ttf、woff 字体文件,原因同 ④ ;
第 ⑥ 部分:
Disallow: /*/comment-page-*
Disallow: /*?replytocom=*
释义:禁止抓取评论分页等相关链接;
Disallow: /category/*/page/
Disallow: /tag/*/page/
释义:禁止抓取收录分类和标签的分页;
Disallow: /*/trackback
释义:禁止抓取trackback等垃圾信息;
Disallow: /feed
Disallow: /*/feed
Disallow: /comments/feed
释义:禁止抓取feed链接,feed只用于订阅本站;
Disallow: /?s=*
Disallow: /*/?s=*\
释义:禁止抓取站内搜索结果;
Disallow: /attachment/
释义:禁止抓取附件页面;
第 ⑦ 部分:Sitemap: http://geekufo.com/sitemap.xml
释义:告知蜘蛛站点地图的位置。
好了基本就到这里,robots.txt 还是需要朋友们根据自己的网站需求 DIY。
最后一点想说的:
- 带 / 比不带 /范围小,比如 /wp-includes 包含 /wp-includes/;
- 本文的灵感和方法一部分来源于张戈博客「纠正静态文件域名robots写法,解决百度搜索不显示缩略图的问题」一文,感谢张戈;
- 本文参考的正式资料在这里:http://www.10.org.cn/wap/i0245865/





挺好的,祝你快乐